Sprachmodelle
Vox verwendet OpenAIs Whisper-Modelle für lokale Spracherkennung. Dieser Leitfaden erklärt die verfügbaren Modelle und wie Sie das richtige für Ihre Bedürfnisse auswählen.
Sprachmodelle Verstehen
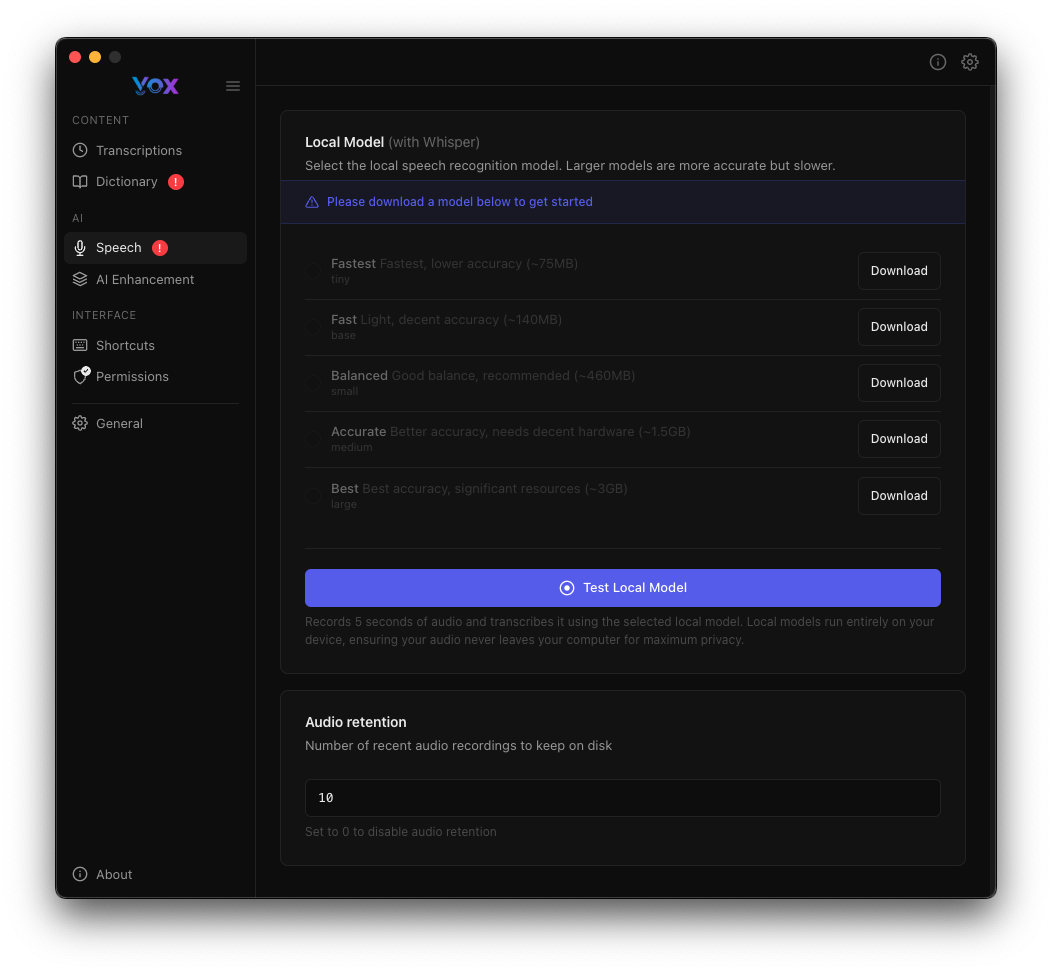
Rufen Sie Sprachmodelle über Einstellungen → Sprache auf.
Was Sind Whisper-Modelle?
Whisper ist OpenAIs Open-Source-System zur automatischen Spracherkennung (ASR). Vox führt diese Modelle lokal auf Ihrem Gerät aus und gewährleistet:
- Datenschutz: Audio verlässt niemals Ihr Gerät
- Offline-Fähigkeit: Funktioniert ohne Internetverbindung
- Geschwindigkeit: Keine Netzwerklatenz
- Kosten: Keine minutenbasierten Gebühren
Datenschutz Zuerst
Alle Spracherkennung findet auf Ihrem Gerät statt. Ihre Sprachdaten werden niemals an externe Server gesendet (es sei denn, Sie aktivieren KI-Verbesserung).
Verfügbare Modelle
Vox bietet fünf Whisper-Modellvarianten, die Geschwindigkeit und Genauigkeit unterschiedlich ausbalancieren:
Am Schnellsten
Größe: ~75MB Geschwindigkeit: Geringste Latenz (<50ms) Genauigkeit: Gut für klare Sprache Ideal für: Schnelle Befehle, kurze Phrasen, Tests
Das kleinste und schnellste Modell. Ideal für Benutzer, die Geschwindigkeit über Genauigkeit stellen oder begrenzten Festplattenspeicher haben.
Schnell
Größe: ~150MB Geschwindigkeit: Sehr geringe Latenz (~50ms) Genauigkeit: Besser als Am Schnellsten Ideal für: Täglicher Gebrauch mit klarer Sprache
Ein guter Mittelweg zwischen Geschwindigkeit und Qualität. Geeignet für die meisten gelegentlichen Transkriptionsbedürfnisse.
Ausgewogen
Größe: ~480MB Geschwindigkeit: Empfohlen (~480MB) Genauigkeit: Gute Allzweck-Genauigkeit Ideal für: Die meisten Benutzer, allgemeine Transkription
Für die meisten Benutzer empfohlen. Bietet hervorragende Genauigkeit für den täglichen Gebrauch ohne übermäßige Ressourcen zu benötigen.
Genau
Größe: ~1,5GB Geschwindigkeit: Bessere Genauigkeit, anständigere Latenz (~1,5GB) Genauigkeit: Hohe Genauigkeit für komplexe Sprache Ideal für: Professionelle Transkription, technische Inhalte, Akzente
Höhere Genauigkeit für schwierige Audiobedingungen, technische Terminologie und verschiedene Akzente.
Bestes
Größe: ~3GB Geschwindigkeit: Höchste Qualität, erhebliche CPU (~3GB) Genauigkeit: Maximale Genauigkeit Ideal für: Kritische Transkription, Mehrsprachigkeit, laute Umgebungen
Das größte und genaueste Modell. Verwenden Sie es, wenn Transkriptionsqualität an erster Stelle steht und die Systemressourcen es erlauben.
Modelle Herunterladen
Ersteinrichtung
Wenn Sie Vox zum ersten Mal installieren, sind keine Modelle heruntergeladen. Sie müssen mindestens ein Modell herunterladen, um Vox zu verwenden.
So laden Sie ein Modell herunter:
- Navigieren Sie zu Einstellungen → Sprache
- Klicken Sie auf Herunterladen neben Ihrem gewählten Modell
- Warten Sie, bis der Download abgeschlossen ist
- Die Schaltfläche wechselt zu "Heruntergeladen", wenn es fertig ist
Erste Modell-Empfehlung
Beginnen Sie mit Ausgewogen für das beste Gleichgewicht aus Qualität und Leistung. Sie können jederzeit weitere Modelle herunterladen.
Mehrere Modelle Herunterladen
Sie können mehrere Modelle herunterladen und zwischen ihnen wechseln:
- Laden Sie verschiedene Modelle für verschiedene Anwendungsfälle herunter
- Testen Sie jedes Modell mit der Schaltfläche Lokales Modell Testen
- Vox verwendet das aktuell ausgewählte Modell (mit einem Häkchen markiert)
- Wechseln Sie jederzeit zwischen Modellen ohne erneutes Herunterladen
Download-Anforderungen
- Internetverbindung: Erforderlich für den erstmaligen Download
- Festplattenspeicher: Stellen Sie ausreichend Platz für Ihr gewähltes Modell sicher
- Zeit: Downloads dauern je nach Modellgröße und Verbindungsgeschwindigkeit 1-10 Minuten
Systemanforderungen
Vox hat unterschiedliche Systemanforderungen je nach Betriebssystem:
macOS
| Anforderung | Minimum | Empfohlen |
|---|---|---|
| Betriebssystemversion | macOS 15 (Sequoia) | macOS 15+ (Sequoia oder neuer) |
| Prozessor | Apple Silicon (M1) oder Intel | Apple Silicon (M2 oder neuer) |
| RAM | 4 GB | 8 GB oder mehr |
| Speicher | 500 MB - 4 GB | 4 GB freier Speicherplatz |
| Berechtigungen | Mikrofon + Bedienungshilfen | - |
Apple Silicon Leistung
Vox läuft deutlich schneller auf Apple Silicon (M1/M2/M3) im Vergleich zu Intel Macs aufgrund optimierter Neural Engine Unterstützung.
Windows
| Anforderung | Minimum | Empfohlen |
|---|---|---|
| Betriebssystemversion | Windows 10 (64-bit) | Windows 11 |
| Prozessor | x64 Prozessor | Moderner Mehrkernprozessor |
| RAM | 4 GB | 8 GB oder mehr |
| Speicher | 500 MB - 4 GB | 4 GB freier Speicherplatz |
| Berechtigungen | Mikrofonzugriff | - |
Windows Leistung
Die Leistung variiert je nach Prozessor. Moderne CPUs (Intel 10. Gen+, AMD Ryzen 3000+) bieten bessere Transkriptionsgeschwindigkeit.
Demnächst
Unterstützung für Linux, iOS und Android ist für zukünftige Versionen geplant. Roadmap ansehen →
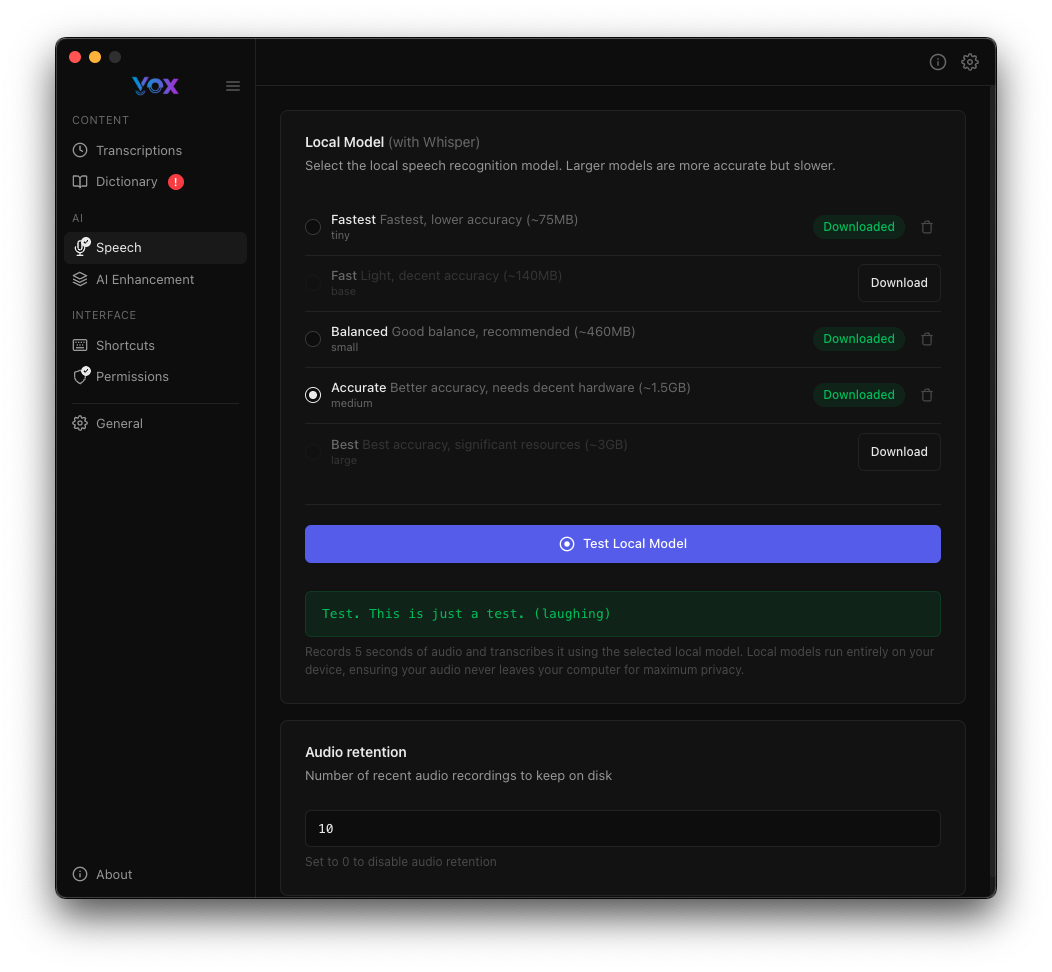
Modelle Testen
Überprüfen Sie nach dem Herunterladen eines Modells, ob es korrekt funktioniert:
- Klicken Sie auf Lokales Modell Testen
- Sprechen Sie eine Testphrase, wenn Sie dazu aufgefordert werden
- Überprüfen Sie das Transkriptionsergebnis
- Suchen Sie nach der Erfolgsmeldung: "Yeah. This is just a test. I laughing"
Der Test überprüft:
- Modell ist korrekt heruntergeladen und installiert
- Audio-Pipeline funktioniert
- Transkriptionsgenauigkeit entspricht Ihren Anforderungen
Mit realem Inhalt testen
Testen Sie mit Phrasen ähnlich Ihrem tatsächlichen Anwendungsfall (technische Begriffe, Namen usw.), um die Genauigkeit zu beurteilen.
Das Richtige Modell Auswählen
Entscheidungsmatrix
| Modell | Größe | Geschwindigkeit | Genauigkeit | Ideal Für |
|---|---|---|---|---|
| Am Schnellsten | 75MB | ⚡⚡⚡⚡⚡ | ⭐⭐⭐ | Tests, einfache Befehle |
| Schnell | 150MB | ⚡⚡⚡⚡ | ⭐⭐⭐⭐ | Täglicher Gebrauch, klare Sprache |
| Ausgewogen | 480MB | ⚡⚡⚡ | ⭐⭐⭐⭐ | Für die meisten Benutzer empfohlen |
| Genau | 1,5GB | ⚡⚡ | ⭐⭐⭐⭐⭐ | Professionelle Arbeit, technische Inhalte |
| Bestes | 3GB | ⚡ | ⭐⭐⭐⭐⭐ | Kritische Transkription, komplexes Audio |
Berücksichtigen Sie Ihren Anwendungsfall
Wählen Sie Am Schnellsten oder Schnell, wenn Sie:
- Sofortige Transkriptionsergebnisse benötigen
- Kurze, einfache Phrasen transkribieren
- Begrenzten Festplattenspeicher haben
- Klar in ruhigen Umgebungen sprechen
Wählen Sie Ausgewogen, wenn Sie:
- Eine gute Allround-Erfahrung möchten
- Sowohl kurze als auch lange Inhalte transkribieren
- Zuverlässige Genauigkeit ohne zu viel Geschwindigkeitseinbuße benötigen
- Unsicher sind, welches Modell Sie wählen sollen (beginnen Sie hier!)
Wählen Sie Genau, wenn Sie:
- Mit technischer Terminologie arbeiten
- Mit Akzent oder in mehreren Sprachen sprechen
- In Umgebungen mit Hintergrundgeräuschen transkribieren
- Hohe Genauigkeit für professionelle Arbeit benötigen
Wählen Sie Bestes, wenn Sie:
- Maximale Transkriptionsgenauigkeit benötigen
- Mit komplexen, mehrsprachigen Inhalten arbeiten
- Kritische Dokumente oder rechtliche Inhalte transkribieren
- Einen leistungsstarken Computer mit reichlich Ressourcen haben
Systemanforderungen
Alle Modelle funktionieren auf jedem Computer, der Vox ausführt, aber die Leistung variiert:
Für Am Schnellsten, Schnell, Ausgewogen:
- Jeder Mac ab 2018 oder später / Jeder moderne Windows-PC
- 8GB RAM Minimum
- Standard-Leistungserwartungen
Für Genau:
- Mac ab 2020 oder später / Windows-PC mit 8 GB+ RAM empfohlen
- 16GB RAM empfohlen
- Kann auf älteren Systemen langsamer sein
Für Bestes:
- Apple Silicon Mac oder moderner Windows-PC mit 16 GB+ RAM
- 16GB+ RAM empfohlen
- Spürbare Verarbeitungszeit bei Transkriptionen erwartet
Apple Silicon Vorteil
Macs mit Apple Silicon (M1-, M2-, M3-Chips) führen Whisper-Modelle aufgrund ihres Neural Engine deutlich schneller aus als Intel-Macs.
Modellleistung
Beispiele für Verarbeitungszeiten
Ungefähre Transkriptionszeiten für eine 10-Sekunden-Aufnahme:
| Modell | Intel Mac (2019) | M1/M2 Mac | M3 Mac |
|---|---|---|---|
| Am Schnellsten | 0,5s | 0,2s | 0,1s |
| Schnell | 1s | 0,5s | 0,3s |
| Ausgewogen | 2s | 1s | 0,5s |
| Genau | 5s | 2,5s | 1,5s |
| Bestes | 10s | 4s | 2s |
Zeiten sind ungefähr und variieren je nach Audiokomplexität
Die Leistung auf Windows-PCs mit vergleichbaren Spezifikationen ist ähnlich.
Genauigkeitsvergleich
Beispiel der Transkriptionsqualität mit technischen Begriffen:
Originalsprache: "Initialize the TypeScript interface with async await handlers"
| Modell | Transkriptionsqualität |
|---|---|
| Am Schnellsten | "Initialize the typescript interface with a sync away handlers" |
| Schnell | "Initialize the TypeScript interface with a sync await handlers" |
| Ausgewogen | "Initialize the TypeScript interface with async await handlers" ✓ |
| Genau | "Initialize the TypeScript interface with async await handlers" ✓ |
| Bestes | "Initialize the TypeScript interface with async await handlers" ✓ |
KI-Verbesserung
Für noch bessere Genauigkeit aktivieren Sie die KI-Verbesserung, um Transkriptionen mit großen Sprachmodellen nachzubearbeiten.
Audio-Aufbewahrung
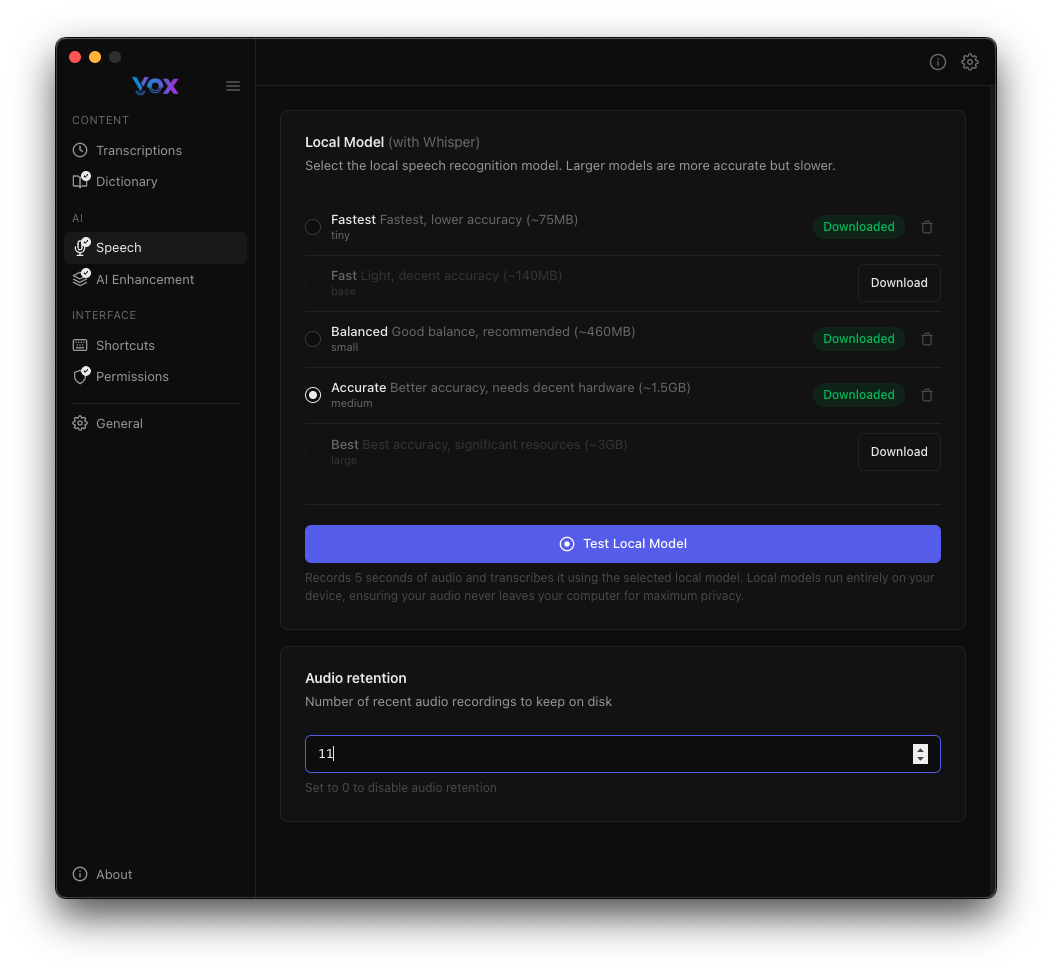
Konfigurieren Sie, wie viele neueste Audioaufnahmen Vox auf der Festplatte behält:
Standard: 10 Aufnahmen
Warum Audio aufbewahren:
- Transkriptionen auf Genauigkeit überprüfen
- Verschiedene Modelle mit demselben Audio testen
- Fehlende Wörter zu Ihrem Wörterbuch hinzufügen
- Transkriptionsprobleme debuggen
Aufbewahrung anpassen:
- Erhöhen, wenn Sie häufig vergangene Aufnahmen überprüfen
- Verringern, um Festplattenspeicher zu sparen
- Auf
0setzen, um die Audio-Aufbewahrung vollständig zu deaktivieren
Datenschutzhinweis
Audioaufnahmen werden lokal im Anwendungsordner von Vox gespeichert. Sie werden niemals gesendet, es sei denn, Sie aktivieren explizit KI-Verbesserungsfunktionen.
Modelle Wechseln
Sie können jederzeit ändern, welches Modell Vox verwendet:
- Navigieren Sie zu Einstellungen → Sprache
- Klicken Sie auf ein anderes heruntergeladenes Modell
- Das Modell mit einem Häkchen ist aktiv
- Ihre nächste Aufnahme verwendet das neue Modell
Kein Neustart erforderlich - die Änderung tritt sofort in Kraft.
Festplattenspeicher Verwalten
Modellspeicher Überprüfen
Modelle werden gespeichert in:
~/Library/Application Support/Vox/models/Modelle Entfernen
Um Festplattenspeicher freizugeben:
- Navigieren Sie zu Einstellungen → Sprache
- Suchen Sie Modelle, die Sie nicht mehr benötigen
- Klicken Sie auf das Papierkorb-Symbol neben dem Modell
- Bestätigen Sie die Löschung
Sie können Modelle jederzeit ohne Strafe erneut herunterladen.
Speichertipps
- Behalten Sie nur die Modelle, die Sie aktiv verwenden
- Das Ausgewogene Modell ist eine gute Einzelmodell-Wahl
- Laden Sie größere Modelle nur bei Bedarf herunter
- Die Audio-Aufbewahrung belegt minimalen Platz (konfigurierbar)
Fehlerbehebung
Modell-Download Fehlgeschlagen
Lösung:
- Überprüfen Sie Ihre Internetverbindung
- Stellen Sie ausreichend Festplattenspeicher sicher
- Versuchen Sie zunächst, ein kleineres Modell herunterzuladen
- Starten Sie Vox neu und versuchen Sie es erneut
Lokaler Modelltest Schlägt Fehl
Lösung:
- Überprüfen Sie, ob die Mikrofon-Berechtigung gewährt ist
- Prüfen Sie Systemeinstellungen → Ton → Eingabe für Mikrofonauswahl
- Versuchen Sie ein anderes Modell
- Starten Sie Vox neu
Schlechte Transkriptionsqualität
Lösungen:
- Auf ein größeres Modell upgraden: Versuchen Sie Genau oder Bestes
- Audioqualität prüfen: Sprechen Sie klar, reduzieren Sie Hintergrundgeräusche
- Benutzerdefinierte Wörter hinzufügen: Nutzen Sie die Wörterbuch-Funktion
- KI-Verbesserung aktivieren: Mit KI nachbearbeiten für bessere Ergebnisse
Modell Benötigt Zu Lange Zum Verarbeiten
Lösungen:
- Auf ein kleineres Modell downgraden: Versuchen Sie Schnell oder Ausgewogen
- Aufnahmen verkürzen: Lange Diktate in kleinere Teile aufteilen
- Andere Apps schließen: CPU-Ressourcen freigeben
- Systemaktivität prüfen: Sicherstellen, dass Ihr Computer nicht stark ausgelastet ist
Modell Nutzt Zu Viel CPU/Arbeitsspeicher
Lösungen:
- Auf ein kleineres Modell wechseln (Am Schnellsten oder Schnell)
- Hintergrundanwendungen schließen
- Audio-Aufbewahrung reduzieren, um Ressourcen freizugeben
- Hardware-Upgrade in Betracht ziehen, wenn Sie größere Modelle benötigen
Fortgeschrittene Themen
Modellarchitektur
Vox verwendet quantisierte Versionen von Whisper-Modellen, optimiert für:
- Optimierte Inferenz auf allen Plattformen
- Reduzierter Speicherbedarf
- Beibehaltene Genauigkeit gegenüber den Originalmodellen
- Apple Silicon Neural Engine-Beschleunigung
Sprachunterstützung
Alle Whisper-Modelle unterstützen mehrere Sprachen, darunter:
- Englisch, Spanisch, Französisch, Deutsch, Italienisch, Portugiesisch
- Chinesisch, Japanisch, Koreanisch
- Und 90+ andere Sprachen
Konfigurieren Sie Spracherkennungssprachen unter Einstellungen → Allgemein → Sprachen.
Benutzerdefinierte Modelle
Derzeit unterstützt Vox nur die fünf integrierten Whisper-Varianten. Unterstützung für benutzerdefinierte Modelle könnte in zukünftigen Versionen hinzugefügt werden.
Nächste Schritte
- KI-Verbesserung aktivieren für bessere Transkriptionsqualität
- Benutzerdefinierte Wörter hinzufügen um die Genauigkeit für technische Begriffe zu verbessern
- Tastaturkürzel konfigurieren für einfache Aufnahme
- HUD-Einstellungen anpassen für besseres Aufnahme-Feedback