Modelos de Voz
Vox utiliza los modelos Whisper de OpenAI para el reconocimiento de voz local. Esta guía explica los modelos disponibles y cómo elegir el adecuado para tus necesidades.
Entendiendo los Modelos de Voz
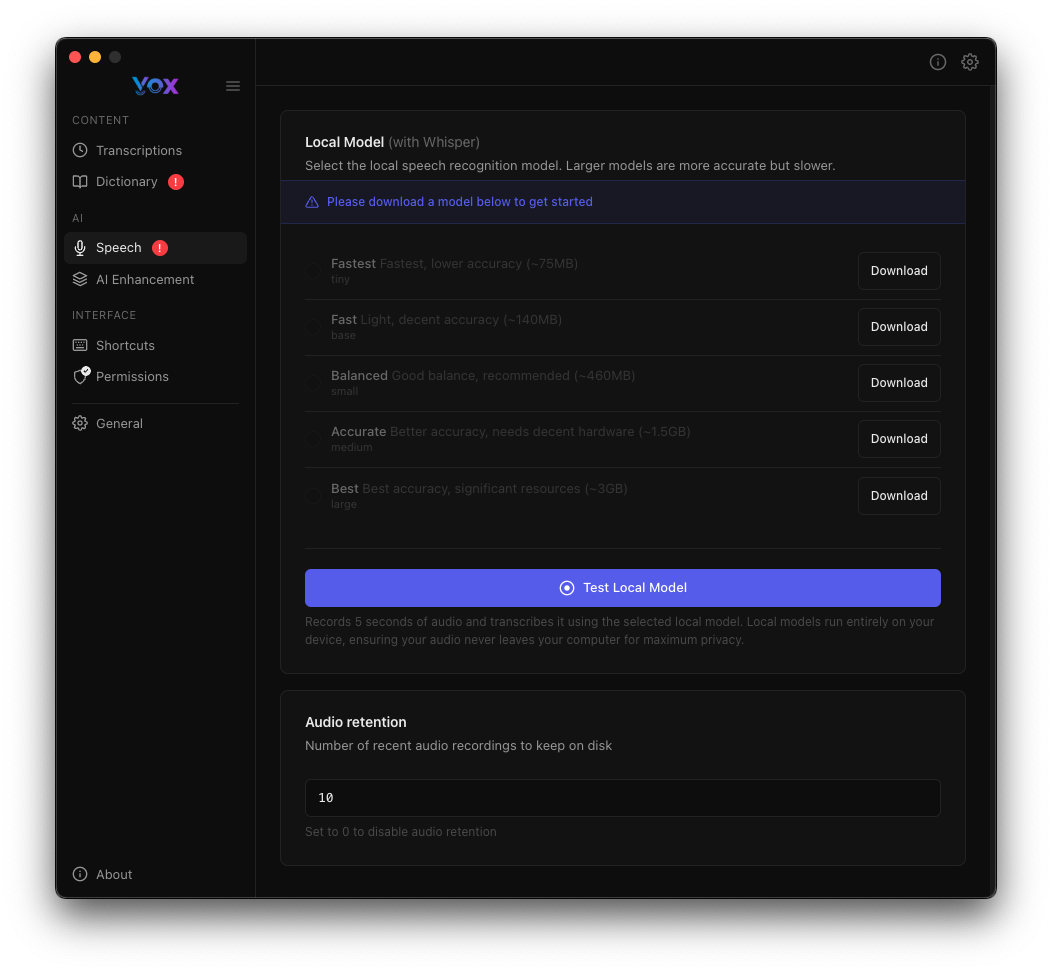
Accede a los modelos de voz desde Ajustes → Voz.
¿Qué Son los Modelos Whisper?
Whisper es el sistema de reconocimiento automático de voz (ASR) de código abierto de OpenAI. Vox ejecuta estos modelos localmente en tu dispositivo, garantizando:
- Privacidad: El audio nunca sale de tu dispositivo
- Capacidad sin conexión: Funciona sin conexión a internet
- Velocidad: Sin latencia de red
- Costo: Sin cargos por minuto
Privacidad Primero
Todo el reconocimiento de voz ocurre en tu dispositivo. Tus datos de voz nunca se envían a servidores externos (a menos que actives la Mejora por IA).
Modelos Disponibles
Vox ofrece cinco variantes del modelo Whisper, cada una equilibrando velocidad y precisión de forma diferente:
Más Rápido
Tamaño: ~75MB Velocidad: Menor latencia (<50ms) Precisión: Buena para voz clara Mejor para: Comandos rápidos, frases cortas, pruebas
El modelo más pequeño y rápido. Ideal para usuarios que priorizan la velocidad sobre la precisión o tienen espacio en disco limitado.
Rápido
Tamaño: ~150MB Velocidad: Latencia muy baja (~50ms) Precisión: Mejor que Más Rápido Mejor para: Uso diario con voz clara
Un buen equilibrio entre velocidad y calidad. Adecuado para la mayoría de las necesidades de transcripción casual.
Equilibrado
Tamaño: ~480MB Velocidad: Recomendado (~480MB) Precisión: Buena precisión de propósito general Mejor para: La mayoría de los usuarios, transcripción general
Recomendado para la mayoría de los usuarios. Proporciona excelente precisión para el uso diario sin requerir recursos excesivos.
Preciso
Tamaño: ~1,5GB Velocidad: Mejor precisión, latencia más decente (~1,5GB) Precisión: Alta precisión para voz compleja Mejor para: Transcripción profesional, contenido técnico, acentos
Mayor precisión para condiciones de audio desafiantes, terminología técnica y varios acentos.
Mejor
Tamaño: ~3GB Velocidad: Mayor calidad, CPU significativo (~3GB) Precisión: Precisión máxima Mejor para: Transcripción crítica, multilingüe, entornos ruidosos
El modelo más grande y preciso. Úsalo cuando la calidad de transcripción es fundamental y los recursos del sistema lo permiten.
Descargar Modelos
Configuración Inicial
Cuando instalas Vox por primera vez, no hay modelos descargados. Debes descargar al menos un modelo para usar Vox.
Para descargar un modelo:
- Ve a Ajustes → Voz
- Haz clic en Descargar junto al modelo elegido
- Espera a que se complete la descarga
- El botón cambia a "Descargado" cuando esté listo
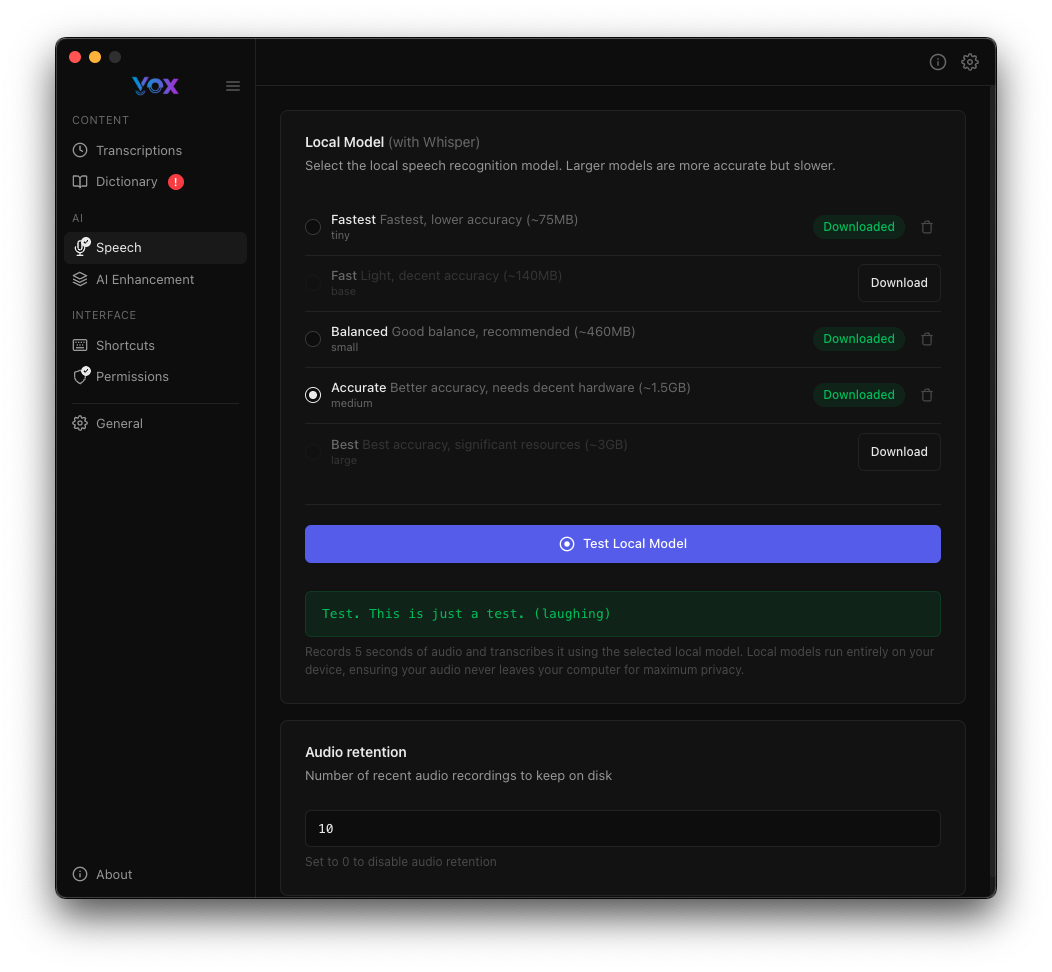
Recomendación de Primer Modelo
Comienza con Equilibrado para el mejor equilibrio entre calidad y rendimiento. Siempre puedes descargar modelos adicionales después.
Descargar Varios Modelos
Puedes descargar varios modelos y alternar entre ellos:
- Descarga modelos diferentes para diferentes casos de uso
- Prueba cada modelo con el botón Probar Modelo Local
- Vox usa el modelo seleccionado actualmente (marcado con una marca de verificación)
- Cambia entre modelos en cualquier momento sin necesidad de volver a descargar
Requisitos de Descarga
- Conexión a internet: Necesaria para la descarga inicial
- Espacio en disco: Asegúrate de tener espacio suficiente para el modelo elegido
- Tiempo: Las descargas suelen tardar de 1 a 10 minutos según el tamaño del modelo y la velocidad de conexión
Requisitos del Sistema
Vox tiene diferentes requisitos del sistema según su sistema operativo:
macOS
| Requisito | Mínimo | Recomendado |
|---|---|---|
| Versión del SO | macOS 15 (Sequoia) | macOS 15+ (Sequoia o posterior) |
| Procesador | Apple Silicon (M1) o Intel | Apple Silicon (M2 o más reciente) |
| RAM | 4 GB | 8 GB o más |
| Almacenamiento | 500 MB - 4 GB | 4 GB de espacio libre |
| Permisos | Micrófono + Accesibilidad | - |
Rendimiento en Apple Silicon
Vox funciona significativamente más rápido en Apple Silicon (M1/M2/M3) en comparación con Macs Intel debido al soporte optimizado del motor neuronal.
Windows
| Requisito | Mínimo | Recomendado |
|---|---|---|
| Versión del SO | Windows 10 (64-bit) | Windows 11 |
| Procesador | Procesador x64 | Procesador multinúcleo moderno |
| RAM | 4 GB | 8 GB o más |
| Almacenamiento | 500 MB - 4 GB | 4 GB de espacio libre |
| Permisos | Acceso al micrófono | - |
Rendimiento en Windows
El rendimiento varía según el procesador. Las CPUs modernas (Intel 10ª gen+, AMD Ryzen 3000+) proporcionan mejor velocidad de transcripción.
Próximamente
El soporte para Linux, iOS y Android está planificado para futuras versiones. Ver hoja de ruta →
Probar Modelos
Después de descargar un modelo, verifica que funciona correctamente:
- Haz clic en Probar Modelo Local
- Di una frase de prueba cuando se te solicite
- Revisa el resultado de la transcripción
- Busca el mensaje de éxito: "Yeah. This is just a test. I laughing"
La prueba verifica:
- El modelo está correctamente descargado e instalado
- El pipeline de audio está funcionando
- La precisión de transcripción satisface tus necesidades
Prueba con Contenido Real
Prueba con frases similares a tu caso de uso real (términos técnicos, nombres, etc.) para evaluar la precisión.
Elegir el Modelo Correcto
Matriz de Decisión
| Modelo | Tamaño | Velocidad | Precisión | Mejor Para |
|---|---|---|---|---|
| Más Rápido | 75MB | ⚡⚡⚡⚡⚡ | ⭐⭐⭐ | Pruebas, comandos simples |
| Rápido | 150MB | ⚡⚡⚡⚡ | ⭐⭐⭐⭐ | Uso diario, voz clara |
| Equilibrado | 480MB | ⚡⚡⚡ | ⭐⭐⭐⭐ | Recomendado para la mayoría |
| Preciso | 1,5GB | ⚡⚡ | ⭐⭐⭐⭐⭐ | Trabajo profesional, contenido técnico |
| Mejor | 3GB | ⚡ | ⭐⭐⭐⭐⭐ | Transcripción crítica, audio complejo |
Considera tu Caso de Uso
Elige Más Rápido o Rápido si:
- Necesitas resultados de transcripción instantáneos
- Transcribes frases cortas y simples
- Tienes espacio en disco limitado
- Hablas claramente en entornos silenciosos
Elige Equilibrado si:
- Quieres una buena experiencia general
- Transcribes contenido tanto corto como largo
- Necesitas precisión confiable sin sacrificar demasiada velocidad
- No estás seguro qué modelo elegir (¡empieza aquí!)
Elige Preciso si:
- Trabajas con terminología técnica
- Hablas con acento o en varios idiomas
- Transcribes en entornos con ruido de fondo
- Necesitas alta precisión para trabajo profesional
Elige Mejor si:
- Requieres precisión máxima de transcripción
- Trabajas con contenido complejo y multilingüe
- Transcribes documentos críticos o contenido legal
- Tienes un computador potente con muchos recursos
Requisitos de Rendimiento del Modelo
Todos los modelos funcionan en cualquier computador que ejecute Vox, pero el rendimiento varía:
Para Más Rápido, Rápido, Equilibrado:
- Cualquier Mac de 2018 o posterior / Cualquier PC Windows moderno
- 8GB de RAM mínimo
- Expectativas de rendimiento estándar
Para Preciso:
- Mac de 2020 o posterior / PC Windows con 8GB+ de RAM recomendado
- 16GB de RAM recomendado
- Puede ser más lento en hardware más antiguo
Para Mejor:
- Mac con Apple Silicon o PC Windows moderno con 16GB+ de RAM
- 16GB+ de RAM recomendado
- Espera tiempo de procesamiento notable en las transcripciones
Ventaja del Apple Silicon
Los Macs con Apple Silicon (chips M1, M2, M3) ejecutan los modelos Whisper significativamente más rápido que los Macs Intel gracias a su Neural Engine.
Rendimiento de los Modelos
Ejemplos de Tiempo de Procesamiento
Tiempos aproximados de transcripción para una grabación de 10 segundos:
| Modelo | Intel Mac (2019) | M1/M2 Mac | M3 Mac |
|---|---|---|---|
| Más Rápido | 0,5s | 0,2s | 0,1s |
| Rápido | 1s | 0,5s | 0,3s |
| Equilibrado | 2s | 1s | 0,5s |
| Preciso | 5s | 2,5s | 1,5s |
| Mejor | 10s | 4s | 2s |
Los tiempos son aproximados y varían según la complejidad del audio
El rendimiento en PCs Windows con especificaciones equivalentes es comparable.
Comparación de Precisión
Ejemplo de calidad de transcripción con términos técnicos:
Voz original: "Initialize the TypeScript interface with async await handlers"
| Modelo | Calidad de Transcripción |
|---|---|
| Más Rápido | "Initialize the typescript interface with a sync away handlers" |
| Rápido | "Initialize the TypeScript interface with a sync await handlers" |
| Equilibrado | "Initialize the TypeScript interface with async await handlers" ✓ |
| Preciso | "Initialize the TypeScript interface with async await handlers" ✓ |
| Mejor | "Initialize the TypeScript interface with async await handlers" ✓ |
Mejora por IA
Para una precisión aún mayor, activa la Mejora por IA para posprocesar transcripciones con modelos de lenguaje grandes.
Retención de Audio
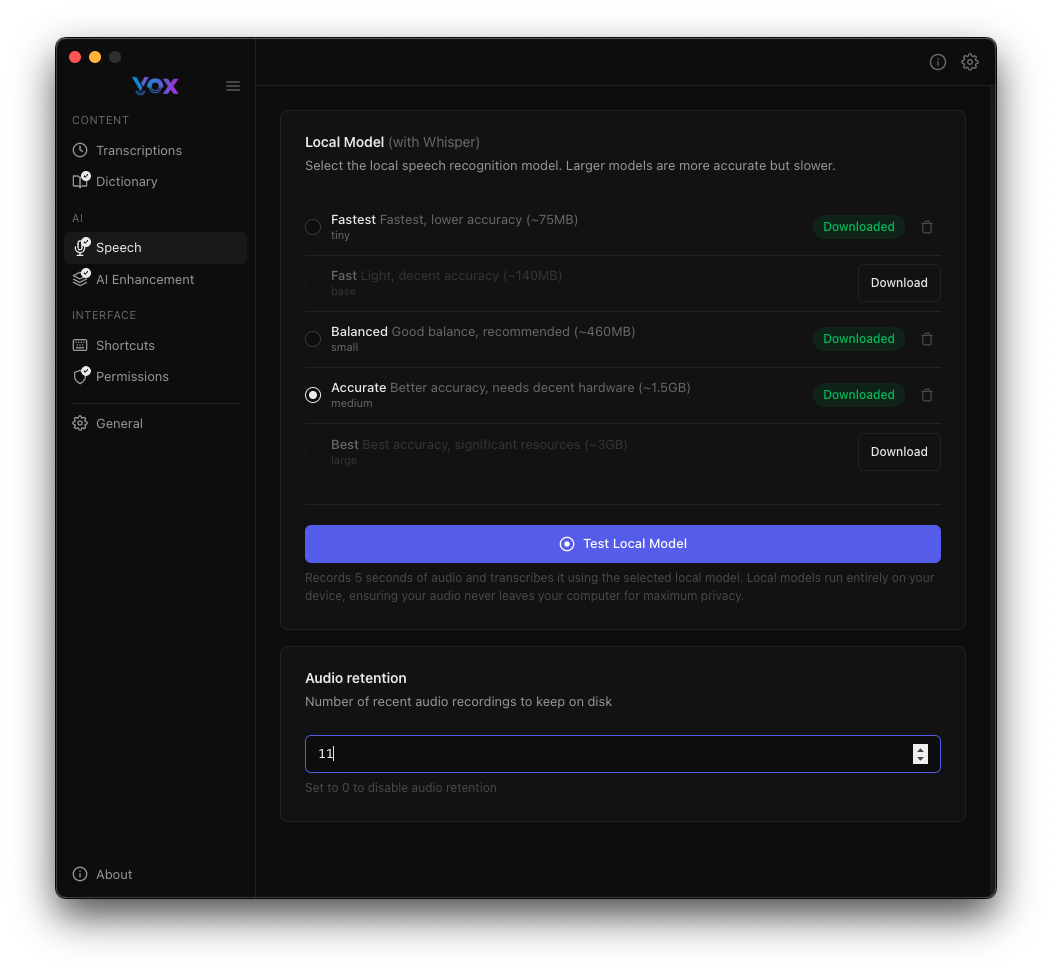
Configura cuántas grabaciones de audio recientes guarda Vox en disco:
Predeterminado: 10 grabaciones
Por qué conservar audio:
- Revisar transcripciones para verificar precisión
- Probar diferentes modelos con el mismo audio
- Agregar palabras perdidas a tu diccionario
- Depurar problemas de transcripción
Ajustar retención:
- Aumentar si frecuentemente revisas grabaciones pasadas
- Reducir para ahorrar espacio en disco
- Establece en
0para deshabilitar la retención de audio completamente
Nota de Privacidad
Las grabaciones de audio se almacenan localmente en la carpeta de la aplicación Vox. Nunca se envían a menos que actives explícitamente las funciones de Mejora por IA.
Cambiar Modelos
Puedes cambiar qué modelo usa Vox en cualquier momento:
- Ve a Ajustes → Voz
- Haz clic en un modelo descargado diferente
- El modelo con marca de verificación está activo
- Tu próxima grabación usará el nuevo modelo
No se necesita reiniciar - el cambio tiene efecto inmediatamente.
Administrar Espacio en Disco
Verificar Almacenamiento de Modelos
Los modelos se almacenan en:
~/Library/Application Support/Vox/models/Eliminar Modelos
Para liberar espacio en disco:
- Ve a Ajustes → Voz
- Encuentra modelos que ya no necesitas
- Haz clic en el icono de papelera junto al modelo
- Confirma la eliminación
Puedes volver a descargar modelos en cualquier momento sin penalización.
Consejos de Almacenamiento
- Mantén solo los modelos que usas activamente
- El modelo Equilibrado es una buena elección de modelo único
- Descarga modelos más grandes solo cuando sea necesario
- La retención de audio ocupa espacio mínimo (configurable)
Solución de Problemas
Descarga del Modelo Falló
Solución:
- Verifica tu conexión a internet
- Asegúrate de tener espacio en disco suficiente
- Intenta descargar un modelo más pequeño primero
- Reinicia Vox e inténtalo de nuevo
Prueba del Modelo Local Falla
Solución:
- Verifica que el permiso de micrófono está otorgado
- Comprueba Preferencias del Sistema → Sonido → Entrada para selección de micrófono
- Prueba con un modelo diferente
- Reinicia Vox
Mala Calidad de Transcripción
Soluciones:
- Actualizar a un modelo mayor: Prueba Preciso o Mejor
- Verificar calidad de audio: Habla claramente, reduce el ruido de fondo
- Agregar palabras personalizadas: Usa la función de Diccionario
- Activar Mejora por IA: Posprocesa con IA para mejores resultados
El Modelo Tarda Demasiado en Procesar
Soluciones:
- Bajar a un modelo más pequeño: Prueba Rápido o Equilibrado
- Acortar grabaciones: Divide dictados largos en partes más pequeñas
- Cerrar otras aplicaciones: Libera recursos de CPU
- Verificar actividad del sistema: Asegúrate de que tu computador no esté bajo carga pesada
Modelo Usando Demasiado CPU/Memoria
Soluciones:
- Cambia a un modelo más pequeño (Más Rápido o Rápido)
- Cierra aplicaciones en segundo plano
- Reduce la retención de audio para liberar recursos
- Considera actualizar tu hardware si necesitas modelos más grandes
Temas Avanzados
Arquitectura del Modelo
Vox usa versiones cuantizadas de modelos Whisper optimizadas para:
- Inferencia optimizada en todas las plataformas
- Menor huella de memoria
- Precisión mantenida frente a los modelos originales
- Aceleración del Neural Engine de Apple Silicon
Soporte de Idiomas
Todos los modelos Whisper soportan múltiples idiomas incluyendo:
- Inglés, Español, Francés, Alemán, Italiano, Portugués
- Chino, Japonés, Coreano
- Y 90+ otros idiomas
Configura idiomas de voz en Ajustes → General → Idiomas.
Modelos Personalizados
Actualmente, Vox soporta solo las cinco variantes Whisper integradas. El soporte de modelos personalizados puede agregarse en versiones futuras.
Próximos Pasos
- Activar Mejora por IA para mejor calidad de transcripción
- Agregar palabras personalizadas para mejorar la precisión de términos técnicos
- Configurar atajos para grabar fácilmente
- Ajustar configuración del HUD para mejor retroalimentación de grabación